-
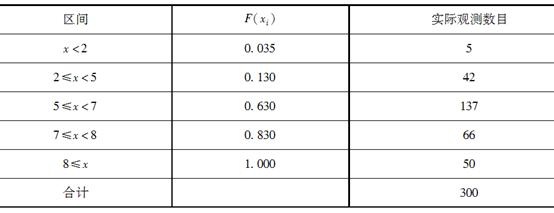
如表所示生存函数表,计算0岁的人在3岁前死亡的概率,以及1岁的人生存到4岁的概率分别为( )。
表 生存函数表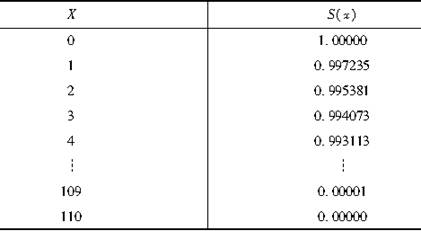
-
如表所示的生命表,计算在2岁与4岁之间的死亡人数,及1岁的人生存到4岁的概率分别为( )。
表 生命表
-
以下表达式中与n|mqx等价的有( )。
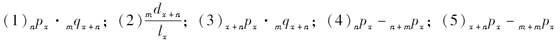
-
已知生命表函数为
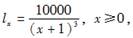 且随机变量T表示x岁人的剩余寿命,则Var(T)=( )。
且随机变量T表示x岁人的剩余寿命,则Var(T)=( )。
-
已知区间(x,x+n]上的中心死亡率为
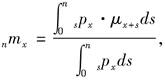 ,则下述表达式与nmx等价的有( )。
,则下述表达式与nmx等价的有( )。

-
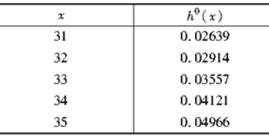
由表中数据求
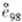 =( )。
=( )。

-
已知某随机变量X的生存函数为
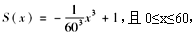 并有E(X)=45,则
并有E(X)=45,则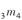 =( )。
=( )。
-
假设某桥梁寿命的分布函数为:
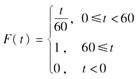
则该桥梁的6m20=( )。
-
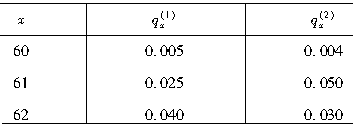
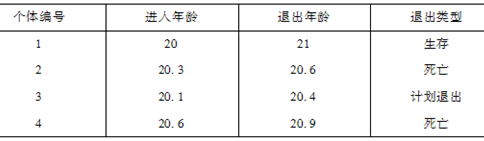
已知X在第i(i=1,2,3,4)年内死亡的概率分布列,如表所示,则2p1=( )。
表 死亡概率分布列
-
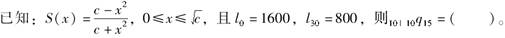
-
已知
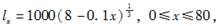 若设X为新生婴儿的剩余寿命,则E(X|X>20)=( )。
若设X为新生婴儿的剩余寿命,则E(X|X>20)=( )。
-
已知
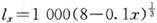 ,0≤x≤80,则20岁人的剩余寿命的方差为( )。
,0≤x≤80,则20岁人的剩余寿命的方差为( )。
-
已知生存模型:

-
已知
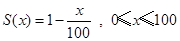 ,则f30=( )。
,则f30=( )。
-
设nfx为活过x岁并在[x,x+n]区间上死亡的人在单位区间上生存的平均年数,已知l25=10000,l30=9600,5m25=0.008,则5f25=( ).
-
己知
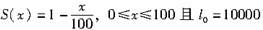 ,则q30和d35的值为( )。
,则q30和d35的值为( )。
-
己知,
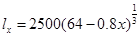 ,则
,则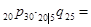 ( )。
( )。
-
如果当30≤x≤35时,
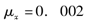 ,则
,则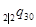 =( )。
=( )。
-
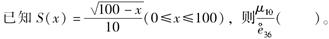
-
25岁到75岁之间死亡的人群中,其中30%在50岁之前死亡;25岁的人在50岁之前死亡的概率为0.2,则25p50=( )。
-
如表所示,则在死亡时间均匀分布假设下,μ62.3=( )。
表 生命表
-
如表1所示,则在死亡时间均匀分布假设下,1.6q98.3=( )。
表1 生命表
-
已知
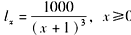 ,则
,则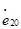 =( )。
=( )。
-
已知某电子装置的寿命服从表的生命表:

假设装置失灵在一年里服从均匀分布,则新装置的期望余命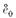 =( )年。
=( )年。
-
已知
 ,则5.25q50分别在死亡时间均匀分布假设、死亡力恒定假设和Balducci假设下概率值之和为( )。
,则5.25q50分别在死亡时间均匀分布假设、死亡力恒定假设和Balducci假设下概率值之和为( )。
-
已知
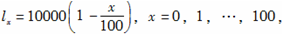 在死亡时间均匀分布的假设下,(0.5q30+μ30.5)/5.25q50=( )。
在死亡时间均匀分布的假设下,(0.5q30+μ30.5)/5.25q50=( )。
-
已知q70=0.40,q71=0.50。f代表在死亡时间均匀分布假设下,70岁人在70.5~71.5岁之间死亡的概率,g代表在Balducci假设下,70岁人在70.5~71.5岁之间死亡的概率,则10000(g-f)=( )。
-
已知lx=12,lx+1=9,假设K为x岁人在Balducci假设下在前1/3年死亡的概率,L为x岁人在死亡时间均匀分布假设下在后2/3年死亡的概率,则K+L=( )。
-
已知:μ70.5=0.01005,μ71.5=0.03046,μ72.5=0.05128。假设死亡在相邻整数年龄间服从均匀分布,则一个70.5岁的人在2年内死亡的概率为( )。
-
已知死亡在年龄期内服从均匀分布,且qx=1,则如下正确的是( )。
(1)0.75qx+0.25=1;
(2)0.25qx+0.5=0.5;
(3)0.25qx=0.25;
(4)0.75px=0.25;
(5)μx+0.5=0.5。
-
在生命表中,已知lx=1000,lx+1=900,在Balducci假设下mx=( ).
-
已知在某生命表中,lx=1000,lx+1=800,则在均匀分布假设下,mx-值为( )。
-
已知由100个现年40岁的人所组成的团体,其中有19人预计在41岁死亡,则在死亡时间均匀分布假设下,
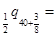 ( )。
( )。
-
已知q35=0.07,μB表示Balducci假设下的死亡力,μUDD表示在死亡时间均匀分布假设下的死亡力,这些假设均在[35,36]区间内有效,

-
下列表达式中正确的是( )。
-
设l40=7746,l41=7681,则在死亡时间均匀分布假设下μ40.25=( )。
-
如表所示为一选择期为3的选择---终极生命表,则1|q[40]=( )。
表 终极生命表
-
已知选择期为4年的选择---终极生命表如表所示,则(1)2|4q[20]+1=____;(2)2|4q[22]+3=____。( )
表 选择—终极生命表
-
已知:l50=8000,l75=4028,l76=3748,则在死亡力恒定假设下,一个50岁的人未来寿命中位数为( )。
-
对于0岁三年选择期的选择—终极生命表,已知:
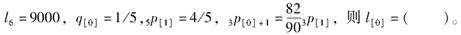
-
下列命题中正确的为( )。
(1)在死亡时间均匀分布假设下,有: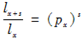 ;
;
(2)fx的含义可由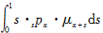 来表达;
来表达;
(3)fx的含义可由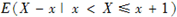 来表达;
来表达;
(4)在死亡时间均匀分布假设下,当 时,有:
时,有: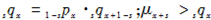 。
。
-
现年76岁的李某在3年前购买了人寿保险,已知选择-终级生命表如表所示,则李某活过80岁的概率为( )。
表 选择—终极生命表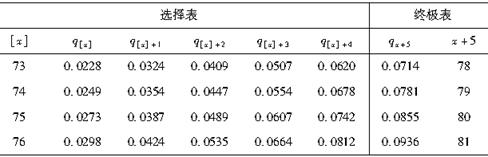
-
假设有选择—终极生命表如表所示,则2p[31]+2-1|q[30]+1( )。
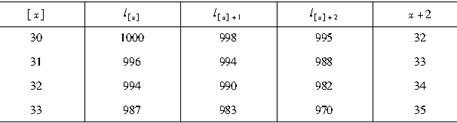
-
已知表所示的选择-终极生命表,则2p[31]+1|q[30]+1=( )。
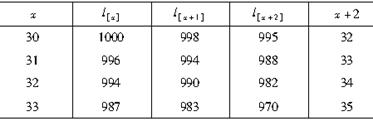
-
假设有甲、乙两位老人今年都是65岁。甲是今年刚刚体检合格购买的保险,乙是10年前购买的保险,至今仍在保险范围内。已知选择—终极生命表如表所示,则利用表估计甲、乙两位老人分别能活到73岁的概率之差为( )。
表 选择—终极生命表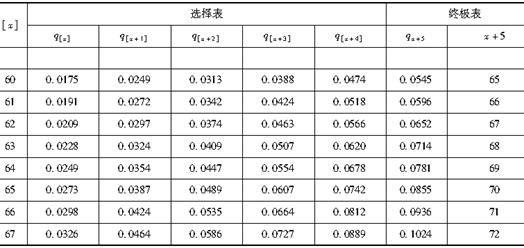
-
如下表是一张选择期为2年的选择—终极生命表:
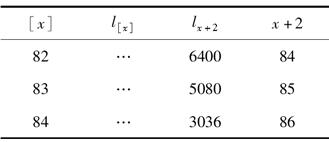
并且对于任意的x都有3·q[x]+1=4·q[x+1],4·qx+2=5·q[x+1]+1,则l[84]==()。
-
对于一张选择期为2年的选择—终极生命表,已知:
(1)q86=0.250,q87=0.375,q88=0.675;
(2)对于任意的x,有:q[x]=0.5qx;
(3)对于任意的x,有:q[x]+1=0.5qx+1;
(4)l[86]=10000。
则l[87]=( )。
-
对于一个2年选择期的选择—终极生命表,如下表所示,又已知:q[x+1]=0.85q[x]+1,q[x+1]+1=0.8qx+2,则3d[51]=( )。

-
设X服从θ=1的指数分布,
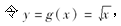 则随机变量Y的危险率函数为( )。
则随机变量Y的危险率函数为( )。
-
令y=g(x)=-lnSX(x),则Y的概率密度函数为( )。
-
设某随机变量X的生存函数为:S(x)=ax3+b,0≤x≤k。若E(X)=45,则Var(X)=( )。
-
设X1与X2是两个相互独立的随机变量,如果Z=max(X1,X2),Y=min(X1,X2),则下列选项错误的是( )。
-
已知随机变量X的危险率函数为h(x)=3x4,x≥0,作变换Y=lnX,则Y的危险率函数为( )。
-
已知随机变量X服从0到20上的均匀分布,fX(x)=1/20,随机变量Y=4X2,则Y的危险率函数hY(16)=( )。
-
设X1与X2是两个相互独立的随机变量,且X1~exp(λ1),X2~exp(λ2),λ1>λ2。设Y=min(X1,X2),Z=max(X1,X2),已知SY(2)=0.24,SZ(2)=0.86,则λ1-λ2=( )。
-
-
寿命X是随机变量,则60岁的人的寿命不超过80岁的概率为( )。
-
已知生存函数为
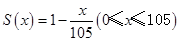 ,则其平均寿命为( )。
,则其平均寿命为( )。
-
已知某细菌的死亡力为
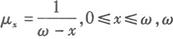 为极限年龄,则其x岁的生存函数是( )。
为极限年龄,则其x岁的生存函数是( )。
-
设
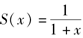 ,则剩余寿命T(y)中位数为( )。
,则剩余寿命T(y)中位数为( )。
-
假设某人群的生存函数为
 则下列计算中,正确的是( )。
则下列计算中,正确的是( )。
(1)一个刚出生的婴儿活不到50岁的概率为0.5;
(2)一个刚出生的婴儿寿命超过80岁的概率为0.8;
(3)一个刚出生的婴儿会在60~70岁之间死亡的概率0.1;
(4)一个活到30岁的人活不到60岁的概率为0.43。
-
已知某群体的生存函数为
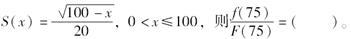
-
已知
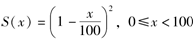 ,则下列计算中正确的是( )。
,则下列计算中正确的是( )。
(1)S(75)=0.0625(2)F(75)=0.9375(3)f(75)=0.5(4)μ75=0.08
-
已知剩余寿命T(x)和T(y)相互独立,且E[T(x)]=E[T(y)]=4,Cov[T(xy),T(
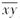 )]=0.09,则E[T(xy)]等于( )。
)]=0.09,则E[T(xy)]等于( )。
-
已知T(0)的分布为:
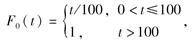 则新生婴儿在30岁和50岁之间死亡的概率为( )。
则新生婴儿在30岁和50岁之间死亡的概率为( )。
-
某一产品的死亡力为μx+t,经一精算师测算,死亡力应修正为μx+t-C。原来的产品损坏概率为qx,死亡力修正后一年内该产品损坏的概率减半,则常数C=( )。
-
设S(x)是生存函数,
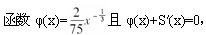 则生存函数S(x)的极限年龄ω为( )。
则生存函数S(x)的极限年龄ω为( )。
-
已知某生存分布为5≤x≤15的双截尾指数分布,参数λ=0.02,该生存分布随机变量未来寿命的中位数为( )。
-
某产品的寿命生存函数为S(x)=1-0.0025x2,0≤x≤20,则该产品中值年龄时的未来期望寿命为( )。
-
已知生存函数为
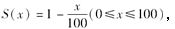 某人现在为30岁,则他在60岁到80岁之间死亡的概率及其平均余命分别为( )。
某人现在为30岁,则他在60岁到80岁之间死亡的概率及其平均余命分别为( )。
-
下列表达式中与kPx等价的是( )。
-
已知死亡服从Makeham死亡分布,h20=0.003,h30=0.004,h40=0.006,则10p10( )。
-
设新生婴儿的生存函数为
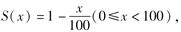 则对于一个40岁的人,下列计算中正确的是( )。
则对于一个40岁的人,下列计算中正确的是( )。
(1)生存函数为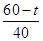 ;(2)死亡力函数为
;(2)死亡力函数为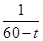 ;(3)密度函数为
;(3)密度函数为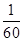 。
。
-
已知生存函数为
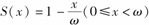 ,且
,且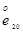 =40,则Var[T(20)]=( )。
=40,则Var[T(20)]=( )。
-
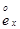 为
为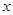 岁的个体的剩余寿命的均值,
岁的个体的剩余寿命的均值,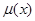 为其死亡力函数,则
为其死亡力函数,则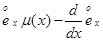 =( )。
=( )。
-
假设X服从[0,10]均匀分布,设中心死亡率为mx,则m5为( )。
-
已知5p10=0.4,且μx=0.01+bx,x≥0,则b等于( )。
-
设死亡力函数为:
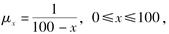 则P(30<x≤35|x>20)=( )。
则P(30<x≤35|x>20)=( )。
-
已知生存函数
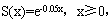 则
则 =( )。
=( )。
-
已知:
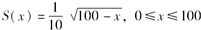 ,则年龄为19岁的人在36岁至75岁之间死亡的概率为( )。
,则年龄为19岁的人在36岁至75岁之间死亡的概率为( )。
-
给定生存分布函数为:
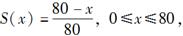 则6m20=( )。
则6m20=( )。
-
现年55岁的李先生,面临两种选择,第一种选择到澳洲安度晚年生活,第二种选择继续定居于国内。在正常情况下,55岁至56岁之间的死亡概率为0.005,而在国外定居,因环境的适应存在额外的风险可表示成附加一个年初值为0.03并均匀递减到年末值为0的死亡效力,则他活到56岁的概率为( )。
-
已知随机变量X的分布函数为:
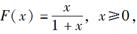 则年龄为20岁的人在30岁到40岁之间的死亡概率为( )。
则年龄为20岁的人在30岁到40岁之间的死亡概率为( )。
-
已知现年18岁的王先生,再生存10年的概率为0.95,再生存30年的概率为0.75,则其现年28岁在达到48岁之前的死亡概率为( )。
-
已知具有两个终止原因的多减因模型,终止力分别为:
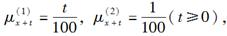 给定状态在t时刻终止,则J的条件分布律正确的为( )。
给定状态在t时刻终止,则J的条件分布律正确的为( )。
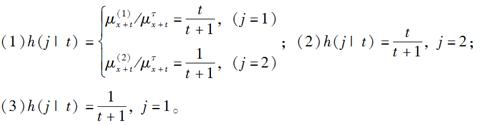
-
一个双减因模型的信息如下:
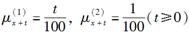 则E(T|J=2)为( )。
则E(T|J=2)为( )。
-
己知
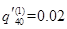 ,
, ,则
,则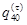 =( )。
=( )。
-
假设
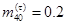 ,
,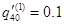 ,在多减因模型中的各减因导致的减少人数服从均匀分布,则
,在多减因模型中的各减因导致的减少人数服从均匀分布,则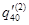 =( )。
=( )。
-
己知某两减因表的以下条件:
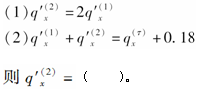
-
已知某三减因表的各减因在各年龄上满足均匀分布假设,

-
已知某三减因表各减因的联合单减因表在各年龄上满足均匀分布,且

-
设对20岁的被保人来说,造成保单衰减的因素仅有1和2两个减因,且
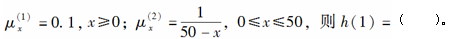
-
设有两个减因,其衰减力均为常数,
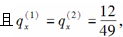 则联合单减因模型中的
则联合单减因模型中的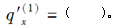
-
设在两减因模型中,每一减因均服从均匀分布,
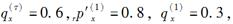 则r=( )。
则r=( )。
-
已知在一个双减因模型中,减因1是退保,减因2是死亡,已知:
 若x=40,则下列说法正确的有( )。
若x=40,则下列说法正确的有( )。
(1)40岁的参保人在70岁时,因为死亡而退出保障的概率为5.3‰;
(2)40岁的参保人在70岁时,无论是因为死亡还是退保,退出保障的总概率只有8‰;
(3)40岁的参保人有23的可能是由于死亡而退出保障;
(4)h(J=2|T=10)=13。
-
对于一个双减因模型,已知:
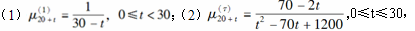 则下列说法正确的有( )。
则下列说法正确的有( )。
(1)第一种减因造成的独立终止率 ;
;
(2)第二种减因造成的独立终止率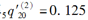 ;
;
(3)总存活概率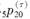 =0.708;
=0.708;
(4)由第一种减因造成的终止概率为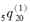 =0.156;
=0.156;
(5)总损失概率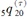 =0.729.
=0.729.
-
对于一个双减因模型,已知独立终止率满足:
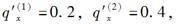 在各伴随单风险模型中,每一个原因在年龄内均服从均匀分布,则终止概率
在各伴随单风险模型中,每一个原因在年龄内均服从均匀分布,则终止概率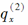 =( )。
=( )。
-
表中的数据为某四年制学校的统计表,该校每届有1000名学生,每一学年学生的状况统计如表所示。
表 某四年制学校统计表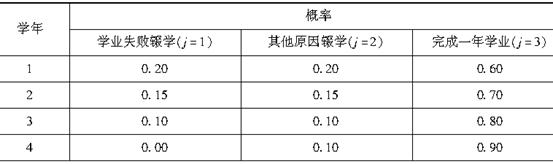 每届学生中,顺利毕业的毕业生人数用变量G表示,学习期间因学业失败辍学的人数,用变量F表示,
每届学生中,顺利毕业的毕业生人数用变量G表示,学习期间因学业失败辍学的人数,用变量F表示,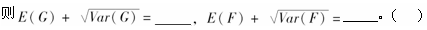
-
对于一个双减因模型,已知:
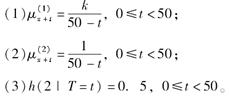
则g(20)=( )。
-
对于一个三减因模型,每一种减因都服从死亡力恒定假设,如表所示。
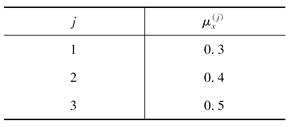
则 =( )。
=( )。
-
已知在一个多减因模型中,死亡力满足:
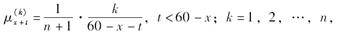 下列说法正确的有( )。
下列说法正确的有( )。
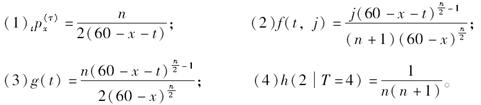
-
设
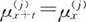 (t≥0;j=1,2,…,m),则下列说法正确的有( )。
(t≥0;j=1,2,…,m),则下列说法正确的有( )。
(1)f(t,j)=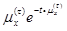 ;
;
(2)h(j)=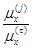 ;
;
(3)g(t)=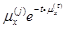 ;
;
(4)T与J的相互独立。
-
有一个两减因生存模型,减因1代表残疾,减因2代表死亡,假定残疾均发生在年末,且残疾发生后,死亡力将恒定为0.02,已知情况如表所示。
则一个60岁的人在3年后残疾但仍然存活的概率为( )。
-
已知三减因生存模型,数据如表所示。

则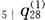 =( )。
=( )。
-
已知一个三减因生存模型,已知:

-
一个三减因生存模型,每一种终止原因在各年龄内均服从均匀分布,已知
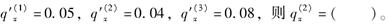
-
对于一个三减因生存模型,已知:
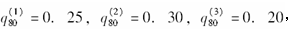 每一种终止原因在各年龄内均服从均匀分布,
每一种终止原因在各年龄内均服从均匀分布,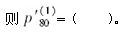
-
对于一个两减因生存模型,已知:
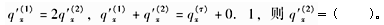
-
某寿险产品所有减因可以归因于死亡(j=1)、残疾(j=2)或者退休(j=3),且各减因的危险率函数在各年龄区间内均为常数。已知年龄为52岁的人独立终止率
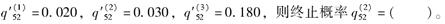
-
一生产商将对其某产品提供保修,保修只针对由于生产商的原因而产生的质量问题。以下是一些关于保修的协议:
(1)所有由于生产商而产生的质量问题都能获得保修;
(2)由于生产商而产生质量问题的死亡力为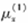 =0.02;
=0.02;
(3)由于其他原因而产生质量问题的死亡力为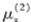 =0.03;
=0.03;
(4)保修期限为n年。
为了使不超过2%的该产品在保修期间内获得保修,则n最大为( )年。
-
有一多减因生存模型,由三种减因构成,已知每种独立原因在各年龄区间内都服从均匀分布,

-
X的剩余寿命受两个终止原因威胁,
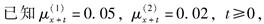 则下列说法正确的有( )。
则下列说法正确的有( )。
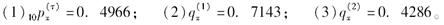
-
一双减因生存模型,终止原因在各年龄内均服从均匀分布,已知终止原因x岁的独立终止率为
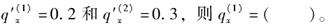
-
已有一双减因模型如表:

如果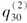 由0.15降低到0.12,则31岁因为原因1而退出保障的个体数会发生( )的变化。
由0.15降低到0.12,则31岁因为原因1而退出保障的个体数会发生( )的变化。
-
给出以下多元减因模型如表:
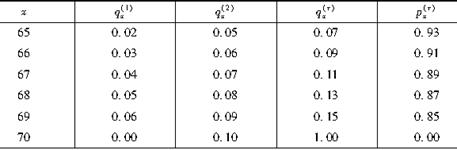
则66岁的被观察者在68岁至69岁之间因原因1离开观察群体的概率与67岁的被观察者在69岁以前因原因2离开观察群体的概率之和为( )。
-
在三减因模型中给出
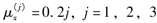 ,则
,则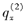 =( )。
=( )。
-
对于两减因生存模型,已知:
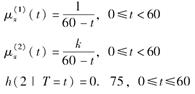
则T的边缘密度函数g(30)=( )。
-
对于一个两减因生存模型,
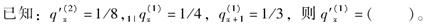
-
已知两减因生存模型:
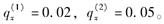 假设在每一年龄的年终止力为常数,则
假设在每一年龄的年终止力为常数,则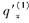 和
和 的值分别为( )。
的值分别为( )。
-
已知:
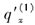 =0.015,
=0.015,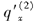 =0.030。减因1(工作中途退职)中终止力服从均匀分布,减因2(工作期间伤残)在年中发生,则
=0.030。减因1(工作中途退职)中终止力服从均匀分布,减因2(工作期间伤残)在年中发生,则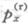 和
和 的值分别为( )。
的值分别为( )。
-
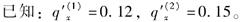 减因1在每一年龄终止力服从均匀分布。已知在一年内减因2发生的条件下,减因2在t=1/6发生的概率为2/3;在t=2/3发生的概率为1/3,则
减因1在每一年龄终止力服从均匀分布。已知在一年内减因2发生的条件下,减因2在t=1/6发生的概率为2/3;在t=2/3发生的概率为1/3,则 =( )。
=( )。
-
考虑两减因生存模型,其终止力如下:
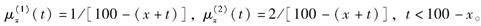 如果x=50,则h(1|T=t)和h(2|T=t)的值分别为( )
如果x=50,则h(1|T=t)和h(2|T=t)的值分别为( )
-
假定X是掷5次硬币国徽面朝上的次数,然后再同时掷X次骰子。设Y是骰子显示数目的总和,则E(Y)+
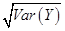 =( )。
=( )。
-
某保单的理赔次数N服从参数为Λ的泊松分布,已知Λ又服从均值为1/4的指数分布,则该保单组合至少发生一次理赔的概率为( )。
-
一个保险人承保的保险标的索赔次数随机变量N服从参数为λ的泊松分布,假设λ服从参数为1的指数分布,那么P(N≤1)=( )。
-
保险人承保了两组风险,A风险组合在每小时发生的理赔次数服从均值为3的泊松过程,B风险组合在每小时发生的理赔次数服从均值为5的泊松过程,两个过程是独立的,则在风险组合B发生3次理赔之前,风险组合A发生3次理赔的概率是( )。
-
某人在一年内感冒的概率服从混合泊松分布,参数λ服从(0,5)上的均匀分布,则他在一年内感冒的次数不少于2次的概率是( )。
-
某汽车一年内发生车祸次数服从混合泊松分布,参数λ服从(0,6)上的均匀分布。那么,该汽车一年内发生车祸的次数不超过1次的概率为( )。
-
假设每次事故的损失的密度函数为
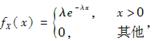 而每份保单规定的免赔额为1/λ,则保险公司对每张保单的理赔额的期望为( )。
而每份保单规定的免赔额为1/λ,则保险公司对每张保单的理赔额的期望为( )。
-
混合指数分布
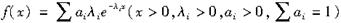 的矩母函数为( )。
的矩母函数为( )。
-
假设某保单规定的免赔额为20,而该保单的损失服从均值为5的指数分布,则理赔额的期望为( )。
-
有100000人参加了汽车车辆险,每车每年发生车辆损失的概率为0.005,则车辆损失在475辆到525辆之间的概率是( )。
-
某保险公司的理赔额统计表明,若某笔理赔额为X元,则变量Y=lnX服从正态分布(理赔额遵从对数正态分布),其均值为6.012,方差为1.792,则某笔理赔额大于1200元的概率与理赔额小于200元的概率之差为( )
-
保险公司为了促进投保人的安全意识,降低损失程度,采用部分理赔的方法。当实际损失为Y元时,理赔额Z=Y-Y0.8。已知该公司承保的某项火灾损失服从对数正态分布,参数μ=10.0;σ2=0.4,则每次火灾的平均理赔额为( )
-
已知某种运输保险2010年的损失额X(单位:万元)服从伽玛分布,参数α=4,θ=0.4,从2010年到2011年的物价通涨率为8%,则2010年,2011年的平均损失额分别为( )。
-
设某种火灾保险每次出险损失额X(万元)具有如下的概率密度函数
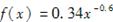
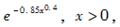 则平均每出险( )次时有一次的损失超过10万元。
则平均每出险( )次时有一次的损失超过10万元。
-
已知某险种的实际损失额X的分布函数为:

若保单规定:损失额低于1000元就全部赔偿,若损失额高于1000元则只赔偿1000元。则被保险人所获得的实际赔付额期望为( )。
-
已知某险种的实际损失额的分布为:

若保单规定免赔额为1,记Y为理赔额,则E(Y)=( )。
-
已知某险种的实际损失额分布为帕累托分布,其密度函数为:
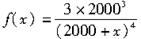 则加入保单中规定免赔额500元后,每次理赔事件中理赔额Y的密度函数为( )。
则加入保单中规定免赔额500元后,每次理赔事件中理赔额Y的密度函数为( )。
-
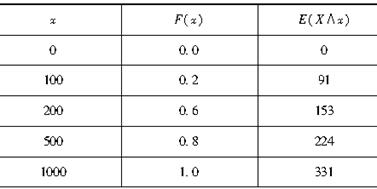
已知某损失额的分布满足的性质如表所示。若保单规定免赔额为100元,记Y为每次理赔事件中理赔额随机变量,则E(Y)=( )。
-
假设某险种的损失额X服从帕累托分布,分布密度为:
 若保单规定了免赔额为500元,保单限额为3000元,记每次损失事件的实际赔付额为Y,则E(Y)=( )。
若保单规定了免赔额为500元,保单限额为3000元,记每次损失事件的实际赔付额为Y,则E(Y)=( )。
-
假设今年的实际损失额为X,X服从均值为10的指数分布。预测明年将会发生通货膨胀,且通货膨胀C的密度函数为:
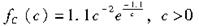 若明年的保单约定保单限额为20,则明年理赔额的期望为( )。
若明年的保单约定保单限额为20,则明年理赔额的期望为( )。
-
假设某险种在2010年的实际损失额服从离散分布,P(X=1000k)=1/6,k=1,…,6。保单上规定每次损失的免赔额为1500元。假设从2010年到2011年的通货膨胀率为5%,2011年的免赔额提高为1600元,则2011年的每次赔偿的理赔额期望与2010年相比,增长率是( )。
-
假设某险种的实际损失额的分布函数为f(x)=0.04xe-0.2x,x>0。已知免赔额为30,则每次损失事故中的平均理赔额为( )。
-
设某险种的实际损失额为X,E(X)=500。当免赔额为d时,投保人的损失消失率(1osseliminationratio)定义为:
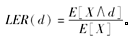 当d=200时,已知LER(200)=25%且P(X≤200)=0.4。则E(X|X≤200)=( )。
当d=200时,已知LER(200)=25%且P(X≤200)=0.4。则E(X|X≤200)=( )。
-
假设某险种的实际损失额的分布如表所示。
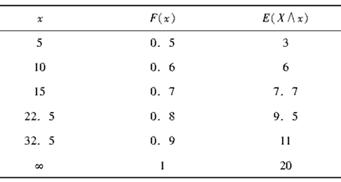
若明年的通货膨胀率为50%,免赔额为15,则理赔额的期望为( )。
-
假设某保险的损失额服从指数分布:
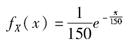 保单规定免赔额为100元,赔偿限额为1000元,赔付比例为0.8。则每次赔偿事件的实际平均理赔额为( )。
保单规定免赔额为100元,赔偿限额为1000元,赔付比例为0.8。则每次赔偿事件的实际平均理赔额为( )。
-
某险种保单在2010年的损失额X满足下面的分布性质:
E(X∧d)=-0.025d2+1.475d-2.25,d=10,11,12,···,26
假设2011年的保单损失额比2010年提高10%。保单规定赔偿高于免赔额11的全部损失,最高的赔偿金额为11,则2011年的平均赔付额比2010年平均赔付额提高了( )。
-
设某险种一张保单的实际损失X的分布密度函数为:f(x)=0.02(1-q+0.02qx)e-0.02x,x>0假设保单规定了免赔额为50,则理赔额的期望为60。若免赔额提高到100,则理赔额的期望为( )。
-
设某险种在2010年的每张保单损失为X,对0≤d≤1000,有下列关系式成立:E[X∧d]=(2000d-d2)/2000。若保单规定保险人支付损失超过100元部分的80%,保单限额为1000元。假设2011年该险种的每张损失提高5%,则2011年该保单的平均赔付额比2010年的平均赔付额提高了( )
-
已知如下条件:
(1)损失服从对数正态分布,参数为μ=5,σ=2;
(2)免赔额为1000;
(3)每年预计的损失数为10次;
(4)损失数与个体损失额互相独立。
如果所有的个体损失额都提高20%而免赔额不变,则每年超过免赔额的平均损失次数为( )。
-
在不采用免赔条款时,损失分布服从表.设原来每次损失的免赔额为10000,免赔额增加后使超过新免赔额的损失数目为超过原免赔额数目的一半,则免赔额增加后每次理赔额的期望较原来免赔额情况下( )。

-
设损失X服从参数分别为α=3和θ=2000的Pareto分布,免赔额d为500,定义
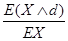 为损失缩减率,则该分布下损失缩减率为( )。
为损失缩减率,则该分布下损失缩减率为( )。
-
假设某险种2010年的每次损失额X服从参数为α=3和θ=2000的Pareto分布。保单约定每次损失的免赔额d为500元。假设从2010年到2011年的通胀率为10%且免赔额保持不变,则2011年比2010年每次损失事件的平均赔付额提高了( )。
-
损失X服从参数为μ=7,σ=2的对数正态分布,假设存在20%的通货膨胀,免赔额为2000,则理赔额的期望是( )。
-
已知损失服从参数为α=3和θ=2000的Pareto分布,如果考虑10%的通货膨胀且保单限额是3000时的平均赔付额与保单限额为3000时的平均赔付额之差为( )。
-
某类保单的索赔额服从参数为α,β=4的帕累托分布,即
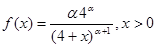 经验显示α的概率分布如表所示。
经验显示α的概率分布如表所示。

该类保单索赔额大于18的概率为( )。
-
随机变量U的矩母函数为MU(t)=(1-2t)-9,t<0.5,则U的方差为( )。
-
某保险人承保的损失随机变量X的概率密度函数为:
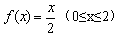
已知 的期望值分别为P0与Pl,则P0+P1=( )。
的期望值分别为P0与Pl,则P0+P1=( )。
-
某医疗保险保单的免赔额为100元,其每次实际损失额X的分布如表所示。则平均理赔额为( )。
表 X的分布列
-
已知损失随机变量X的分布函数为:
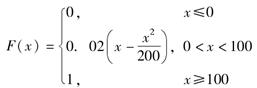
将随机变量Z定义为损失超过免赔额10的60%,则E(Z)=( )。
-
已知某险种的损失变量X的概率分布,如表所示。假设保险人的赔付额为损失超过免赔额50的80%,保单限额为250,则赔付额的期望为( )。
表 损失变量X的概率分布
-
假设某风险的损失X服从Pareto分布,α=3,θ=1000,即
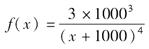
若保单规定免赔额为d=250。假设损失次数N服从负二项分布,k=2,p=1/4。设N*表示理赔次数,则Var(N*)=( )。
-
设X表示损失的随机变量,且f(x)=0.1e-0.1x(x>0),若定义
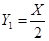 与
与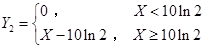 ,则E(Y1)-E(Y2)=( )。
,则E(Y1)-E(Y2)=( )。
-
某保险公司承保了如下特性的保单组合:
(1)每张保单最多发生一次索赔,并且索赔发生的概率为0.02;
(2)索赔发生时的个体理赔额分布如下:
表 个体理赔额分布 (3)安全附加系数为1/3。
(3)安全附加系数为1/3。
为了使所收取保费总额低于赔付总额的概率不超过5%,保险公司需承保的最小保单数是( )。[2008年真题]
-
在个体风险模型中,已知一个保险公司保单组合的理赔总额S的分布函数,如表所示。
表 理赔总额S的分布列
已知每张保单的理赔额单位为100。其中一张保单的理赔额分布为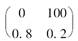 。当此保单的理赔额的分布变为
。当此保单的理赔额的分布变为 时,该保单组合在调整后的总理赔额不超过500的概率为( )。[2008年真题]
时,该保单组合在调整后的总理赔额不超过500的概率为( )。[2008年真题]
-
设X服从[0,100]上均匀分布,Y服从[0,200]上均匀分布,X与Y相互独立,令S=X+Y,并记FS(x)为S的概率分布函数,FS(220)等于( )。[2008年真题]
-
设聚合理赔S服从参数为λ=2的复合泊松分布,个别理赔额变量X的分布如下:
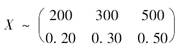
则P/{S≤500/
-
一个群体由70个男性和30个女性组成,假设70个男性的体重均为75公斤,30个女性的体重均为55公斤。从群体中任选一个个体,体重记为W,则Var(W)+E(W)=( )。
-
某保险公司承保了1500个相互独立的保单,每个保单最多发生一次损失。在所有保单中,每个保单发生损失的概率为0.25,保单发生损失后,损失额的期望和方差分别为400和300,利用正态分布(标准正态分布表)近似计算总损失额超过151000的概率为( )。
-
保险公司曾经承保A和B两种特定风险。依据多年来对于理赔次数的统计研究发现,A类保单的赔款频率为0.02,B类保单的赔款频率也接近于0.02。保险公司计划推出一项新的保险险种,将同时承保这两种风险,并将A、B两种保单划归入这项新险种。已知A类保单有100000张,B类保单有150000张。假定两种风险理赔的发生是相互独立的。则这250000张保单中发生理赔的保单数目的期望及标准差分别为( )。[样题]
-
保险公司为5000个投保人提供某种医疗保险。设他们的医疗花费相互独立,且约定当花费超过100元时,保险公司赔偿超过100元的部分,当花费小于100元时,自己负担。已知每个投保人的医疗花费服从如表所示的分布。
表 每一个投保人的医疗花费分布列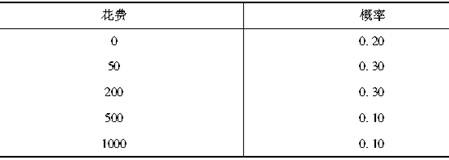
若安全附加系数θ=5%,则该险种没有利润的概率为( )。
-
已知随机变量X1,X2,X3,X4相互独立,Xk的密度函数为
 则
则 为( )。[2008年真题]
为( )。[2008年真题]
-
假定理赔次数N服从几何分布,概率分布为P(N=n)=pqn,n=0,1,2,…,0<p<1,p+q=1;个别理赔额X服从参数为β的指数分布Exp(β),聚合理赔S的矩母函数MS(t)等于( )。[2008年真题]
-
对于理赔总量S,已知:
(1)P(10<S<20)=0;
(2)E[I10]=0.60;
(3)E[I20]=0.20。
其中Id为限额损失再保险下自留额为d时的再保险人的理赔额。FS(10)为( )。[2008年真题]
-
已知理赔总量S服从参数为N=12,p=0.25的二项分布,保险人会支付红利

G为总保费,且已知k=0.8,G=5,则E(D)等于( )。[2008年真题]
-
随机变量X服从均值为1000的指数分布,某类保单的损失Y为:
 保险人对这类保单损失的免赔额为200。保险人赔付随机变量的均值为( )。[2008年真题]
保险人对这类保单损失的免赔额为200。保险人赔付随机变量的均值为( )。[2008年真题]
-
一种保单组合,至多可能发生一次理赔,概率为0.1,并且:
(1)发生时刻T在[0,50]之间均匀分布;
(2)总理赔额S的概率分布为:P(S=1000)=0.8,P(S=5000)=0.2。
设保险人的盈余过程为U(t)=900+100t-S(t),则破产概率为( )。[2008年真题]
-
已知某医疗保险损失额X服从对数正态分布ln(u,σ2),其中参数μ和σ未知。现随机抽取10样本,已知
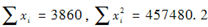 。用矩估计法估计参数μ和σ,则
。用矩估计法估计参数μ和σ,则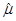 -
- =( )。
=( )。
-
已知某医疗险种的理赔额样本如表所示。
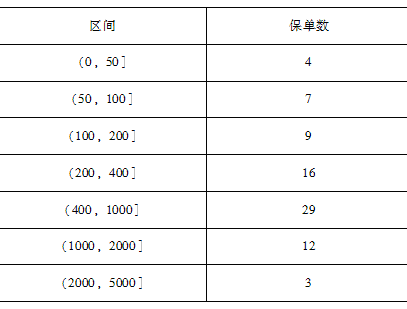
则样本60%的分位数为( )。
-
已知损失额的分布函数为:
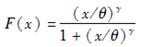
其中θ和γ为未知参数。现随机抽取11个样本:
10,35,80,86,90,120,158,180,200,210,1500
用40%和80%分位数估计参数θ和γ,则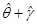 =( )。
=( )。
-
已知某险种的理赔数据如表所示。

假设理赔额服从参数为θ的指数分布,则参数θ的极大似然估计值为( )。
-
已知损失额X服从单参数的Pareto分布,其分布密度函数为:
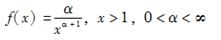
随机抽取5个样本,其中2个样本都超过了25,但具体数额未知,另外3个样本分别为3,6和14。则参数α的极大似然估计为( )。
-
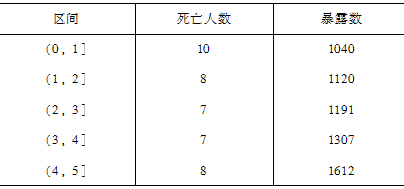
在某次研究中,运用矩估计法,在给定的暴露数总数的基础上,在估计区间(x,x+1]上观察到的死亡人数如表1所示。由所给样本数据估计
 分别为( )。
分别为( )。
表1
-
在x岁的样本中,nx=14200,cx=4400个对象预计在
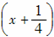 岁结束,观察得
岁结束,观察得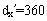 是在岁之前的cx中的死亡人数,
是在岁之前的cx中的死亡人数,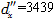 是在(x+1)岁之前剩下的观察人群nx-cx中的死亡人数,假设在区间(x,x+1]上的死亡力为常数,则qx的极大似然估计量为( )。
是在(x+1)岁之前剩下的观察人群nx-cx中的死亡人数,假设在区间(x,x+1]上的死亡力为常数,则qx的极大似然估计量为( )。
-
考察从20岁开始进入估计区间(20,21]上的100个观察对象,在这区间上发生了两次退出,一次在20.2岁,一次在20.7岁,另有一次死亡发生在20.3岁,剩下97人都生存到了21岁。则在下列情况下:(1)完全数据,指数分布;(2)完全数据,均匀分布,且两次的退出年龄取为平均年龄20.45岁;
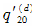 的极大似然估计分别为( )。
的极大似然估计分别为( )。
-
在区间(0,4]上的两个观察对象,已知一人在t=1时死亡,另一人在观察期结束时仍生存,已知生存函数
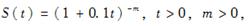 则m的极大似然估计为( )。
则m的极大似然估计为( )。
-
80个18岁的刚进入大学的某专业学生,在(18,19]上有2人加入中国共产党,入党时间分别为18.2岁与18.8岁,作为普通学生78人生存到19岁。假设入党的力度为常数,则18岁的人在一年内入党的概率的极大似然估计为( )
-
假定一样本有n个观察对象,从t=0开始观察,得到它们的死亡时间为t1,t2,…,tn,死亡时间相互独立。则指数分布模型S(t)=e-λt的参数λ的极大似然估计量为( )。
-
由10只实验老鼠组成的样本,其死亡时间(以天为单位)为:3,4,5,7,7,8,10,10,10,12。假定适合的生存模型为指数分布(密度函数为f(t)=λe-λt,t>0),则运用矩方法和中位数估计法来估计参数λ分别为( )。
-
已知10个样本的死亡时间为3,4,5,7,7,8,10,10,10,12。假设适合的生存模型为参数λ的指数分布,用最小二乘法估计参数λ为( )。
-
已知在年龄区间(24,25]上发生了3次死亡,死亡年龄分别为:24.50,24.60,24.75;并且对所有的死亡观察对象的预计观察期都超过25岁。己知
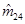 =0.025,则q24的矩估计为( )。
=0.025,则q24的矩估计为( )。
-
在年龄区间(x,x+1]上,已知在x岁时有150个观察对象进入观察,在(x+
 )时有12个观察对象进入观察且在该区间上共观察到8个死亡对象。则在年龄内死力为常数的假设下,区间(x,x+1]上的死亡概率qx的矩估计为( )。
)时有12个观察对象进入观察且在该区间上共观察到8个死亡对象。则在年龄内死力为常数的假设下,区间(x,x+1]上的死亡概率qx的矩估计为( )。
-
在年龄区间(x,x+1]上,当0≤s≤0.6时,spx=e-0.2s;当0.6<s≤1时,spx=1-0.2s·qx。如果nx=90,并且有两次死亡分别发生在(x+0.45)与(x+0.85)处,则qx的极大似然估计为( )。
-
考察4只注射了某抗体的兔子,其中3只在2010年12月31日之前死亡,观察期为日历年2010年,具体数据如表所示。则在指数生存模型下的参数μ的极大似然估计为( )。
-
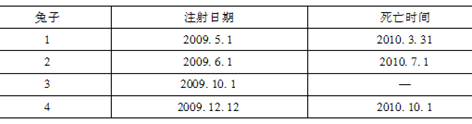
考察某老年人俱乐部中的四位百岁老人,其中在2010年12月31日之前有1人死亡,2人退出,观察期为日历年2010年,具体数据如表所示。假定死亡率服从指数分布,离开服从均匀分布U(0,w),则服从均匀分布模型的参数w的极大似然估计为( )。
-
对于评估区间(x,x+1],假定:
如果nx=200,并且观察到2个死亡者,一个死亡发生在x+0.5岁,另一个死亡发生在x+0.86岁,则qx的极大似然估计为( )。
-
已知样本观察数据如表所示。
如果样本来源于Gompertz分布,已知该分布的危险率函数为:
h(x)=Bcx(x≥0,B>0,c>1)
使用最小二乘法估计参数B与c分别为( )。
-
对100只动物在t=0时开始观察,并在t=5处截尾,在截尾之前观察到5只动物的死亡时间为:1,3,4,4.1,4.3。已知生存函数为:
 则a的极大似然估计为( )。
则a的极大似然估计为( )。
-
有一个4人被观察群体,在(20,21]之间具有如表所示的记录。
在死力常数假设下,p20的极大似然估计为( )
-
跟踪观察一个医院中在同一天出生的5名婴儿,死亡时间分别为:2,4,8,16,32,若他们的死亡力服从年龄的线性函数,即μx=αx,利用极大似然估计法α为( )。
-
已知索赔额分布服从伽玛分布,其密度函数为
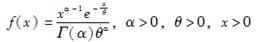
随机的10个索赔额样本:1500、6000、3500、3800、1800、5500、4800、4200、3900、3000,则用矩估计法估计的参数θ和α分别为( )。
-
假设索赔额分布为帕累托分布,其密度函数为
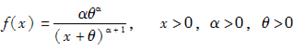
随机20个索赔额样本为:27、82、115、126、155、161、243、294、340、384、457、680、855、877、974、1193、1340、1884、2558、15743,利用矩估计得到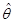 和
和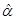 ,则
,则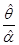 为( )。
为( )。
-
X是密度为f(x)=pxp-1(0<x<1)的连续随机变量,一组随机样本的三次观测为0.2、0.3、0.5,则利用极大似然估计得到的
 =( )。
=( )。
-
假设索赔额分布为指数分布
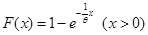 随机20个索赔额样本为:27、82、115、126、155、161、243、294、340、384、457、680、855、877、974、1193、1340、1884、2558、15743,则运用中位数估计法估计参数θ为( )。
随机20个索赔额样本为:27、82、115、126、155、161、243、294、340、384、457、680、855、877、974、1193、1340、1884、2558、15743,则运用中位数估计法估计参数θ为( )。
-
一组分组数据具有如下性质:(0,5]-n1=2,(5,10]-n2=2,(10,25]-n3=2,(25,∞)-n4=2,运用极大似然估计方法估计指数分布的参数θ为( )。
-
以下是对于限额为20的保单的10次赔付额:3、5、6、8、9、13、16、20、20、20(三个20均为赔偿限额,所以这三次的损失额都大于20)。假设损失额服从[0,θ]的均匀分布,则运用矩估计方法得到的=( )。
-
对于估计区间(x,x+1],有5个个体构成的群体的观测数据如表所示。
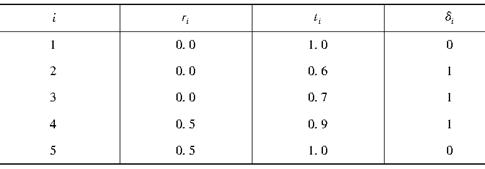
其中x+ri是第i个个体进入(x,x+1]区间的年龄;x+ti是第i个个体或生存退出年龄,或者死亡年龄,或者观察到的退出时的年龄;δi=0表示被观测个体是生存者,δi=1表示被观测个体死亡。则在指数分布假设下算得的qx的极大似然估计与均匀分布假设下算得的qx的极大似然估计之差为( )。
-
对患有急性白血病的21名病人的病情缓解时间进行观察,得到数据如下1,1,2,2,3,4,4,5,5,6,8,8,9,10,10,12,14,16,20,24,34,(单位为月),进行拟合优度检验。选定原假设:病情缓解时间的分布的密度函数为:

则χ2统计量的值为( )。
-
某随机变量的5个观测分别为1,2,3,5,13,原假设:f(x)=2x-2e-2/x,x>0,则K-S检验统计量Dn的值为( )。
-
给定以下5个来自同一随机样本的观测值:0.1,0.2,0.5,1.0,1.3,对于零假设:总体的密度函数是f(x)=2(1+x)-3,x>0,则K-S检验统计量Dn的值为( )。
-
对150名投保人,从签订保单受益凭证开始观察,直到其身故,且没有删失观测值,有21人在第1年身故,有27人在第2年身故,有39人在第3年,另有63人在第4年。考虑原假设为生存模型
在5%的显著性水平下,进行拟合优度检验,则χ2统计量的值为( )。
-
365天的索赔数记录为:50天没有索赔,122天有1个索赔,101天有2个索赔,92天有3个索赔,没有1天发生4次以上的索赔。假定服从参数为λ的Poisson模型,则利用最大似然估计得出
 为____,进行
为____,进行 拟合优度检验,统计量的值为____。( )
拟合优度检验,统计量的值为____。( )
-
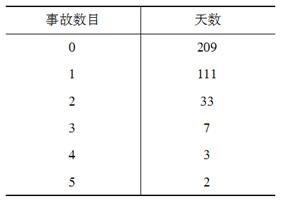
一年内每天发生的事故数分布如表所示,考虑如下的假设检验:数据来自均值为0.6的Poisson分布,将数据分为尽可能多的组,并保证每个组期望的观测数至少为5。采用χ2拟合优度检验,则χ2统计量的值为( )。
-
用200份赔付数据拟合一个帕累托分布,给定:(1)对应的极大似然估计是
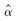 =1.4和
=1.4和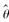 =7.6(2)以极大似然估计值算得的对数似然函数值是-817.92;(3)∑ln(xi+7.8)=607.64。若使用似然比检验对原假设α=1.5和θ=7.8进行检验,则检验统计量的值为( )。
=7.6(2)以极大似然估计值算得的对数似然函数值是-817.92;(3)∑ln(xi+7.8)=607.64。若使用似然比检验对原假设α=1.5和θ=7.8进行检验,则检验统计量的值为( )。
-
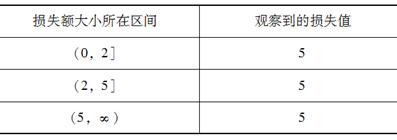
表是一个包含15个损失数据的样本。已知损失额大小服从(0,θ)区间上的均匀分布。记Ej是第j个区间上的损失次数的期望值,Oj是第j个区间上损失次数的实际观测值。若通过最小化
 来估计θ,得到的为( )。
来估计θ,得到的为( )。
-
假设赔付的大小服从指数分布。随机选取5个赔付样本31、66、85、135、180。使用矩估计获得指数分布的参数,则对应的Kolmogorov-Smirnov检验统计量为( )。
-
给定以下包含30个数据的汽车索赔额数据:54、140、230、560、600、1100、1500、1800、1920、2000、2450、2500、2580、2910、3800、3800、3810、3870、4000、4800、7200、7390、11750、12000、15000、25000、30000、32300、35000、55000。原假设为索赔额的分布服从一个分位数如表所示的连续分布F(x)。检验时在保证每组期望的观测数至少有5个数据的前提下分成尽可能多的组,则计算卡方拟合优度检验统计量的值为( )。

-
给定下列观测值的一个样本:0.1、0.2、0.5、0.7、1.3。为了检验对应的概率密度函数为
这个假设,则相应的Kolmogorov-Smirnov检验统计量为( )。
-
设原假设为给定的数据来自一个已知分布F(x),如表所示,则相应的χ2拟合优度检验,在2.5%的显著水平下和在1%的显著水平下,检验的结果分别为( )。
-
韦伯分布的密度函数为
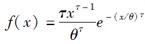
来自服从韦伯分布的总体的样本如下:595、700、789、799、1109。已知在θ和τ的极大似然估计点,∑ln(f(xi))=-33.05。当τ=2时,θ的极大似然估计是816.7。用似然比检验做一下检验H0:τ=2,H1:τ≠2,则在5%的显著水平下和在2.5%的显著水平下分别是( )。
-
来自总体X的包含12个数据的样本为:7、12、15、19、26、27、29、29、30、33、38、53。用于拟合的模型是参数为
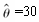 的指数分布。基于上述数据找出在区间[0,1]上,该p-p图与y=x的图像之间垂直方向上的最大离差为( )。
的指数分布。基于上述数据找出在区间[0,1]上,该p-p图与y=x的图像之间垂直方向上的最大离差为( )。
-
一个来自服从参数
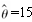 的指数分布的总体的样本包含8个数据:3、4、8、10、12、18、22、35,则求Anderson-Darling统计量的值为( )。
的指数分布的总体的样本包含8个数据:3、4、8、10、12、18、22、35,则求Anderson-Darling统计量的值为( )。
-
一组保单数为50的风险集的索赔数以如表1分组数据形式给出。记“H0:各风险的索赔数服从0、1、2、3、4上的离散均匀分布”,则使用χ2拟合优度检验去检验这个原假设得出χ2统计量的值为( )。
表1

-
使用参数为
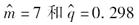 的二项分布拟合表1中的数据,并用χ2拟合优度检验去检验原假设得出χ2统计量的值为( )。
的二项分布拟合表1中的数据,并用χ2拟合优度检验去检验原假设得出χ2统计量的值为( )。
表1

-
一个随机抽取的样本包括100个数据,用指数分布拟合时,以极大似然估计去求分布的参数,此时极大化的似然函数值为-159.4。继续用伽玛分布拟合这组数据,如果根据似然比检验,伽玛分布的拟合效果在5%显著性水平下优于指数分布的话,则用极大似然估计求伽玛分布模型的参数时,最大化的似然函数值至少为( )。
-
一个来自总体X的样本包含12个数据:7、12、15、19、26、27、29、29、30、33、38、53。假设数据在32处删失,并使用参数为
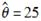 的指数分布拟合这组数据,则对应的K-S检验统计量的值为( )。
的指数分布拟合这组数据,则对应的K-S检验统计量的值为( )。
-
个损失数据以千为单位被汇总如表1所示。原假设为“损失额(以千为单位)的分布服从密度方程f(x)=x-2,x>1”,则对原假设进行χ2拟合优度检验,其对应检验统计量的值为( )。
表1
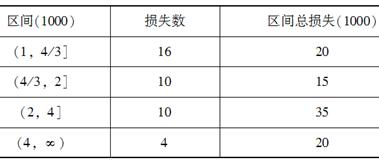
-
对模型A和B进行似然比检验。已知A是单参数模型,B不止一个参数。进行完参数估计后,两模型的对数似然函数值分别是lA=-280和lB=-276。如果检验的结果是在5%显著性水平下B优于A,则B的参数最多能有( )个。
-
在移动加权平均修匀法(M-W-A)中,若z=0,则系数ar=( )。
-
已知
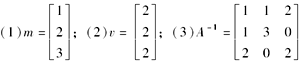 。运用K-J修匀法,求(A+B)-1(u-m)=( )。
。运用K-J修匀法,求(A+B)-1(u-m)=( )。
-
已知M-W-A公式为:
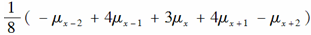 ,则
,则 与
与 之比为( )。
之比为( )。
-
设T=(T1,T2,T3)是随机向量,其中T1,T2,T3相互独立。其先验均值m=[4,8,10]′,观察值为u=[2,6,14]′,协方差矩阵和条件协方差矩阵分别为:
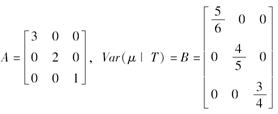
则用K-J法求得的修匀向量v=( )。
-
已知Everett公式具有四次精确度,且该公式是相切的,则C(1/2)=( )。
-
考虑某野生动物群体,已知其死亡分布列如表所示。若采用Gompertz形式进行参数修匀,则μx=BCx中的参数C=( )。

-
设z=1,h=2,u′=[2,2,12,16],v′=[3,4,10,14],则
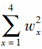 =( )。
=( )。
-
用Everett四点公式修匀ux得到vx,已知:
(1)A(S)是线性的;
(2)此公式是相切的;
(3)此公式是密切的;
(4)B(S)是次数不超过3次的多项式;
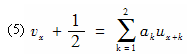
则系数a2=( )。
-
如Vx=δ4Ux,假设各个Ux是独立的且有相同的方差σ2,则E[Vx]和Var(Vx)分别为( )。
-
如果Vx=δ2Ux+δ4Ux,假设各个Ux是独立得且有相同的方差σ2,则Var(Vx)=( )
-
对z=2和n=6.矩阵K2′K2=( )。
-
设z=1,h=2。
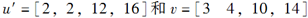 ,则
,则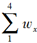 =( )。
=( )。
-
设z=h=3和对所有x有wx=2。如果u′=[1,8,27,25]则将u4表为v的分量的线性组合为( )。
-
记u′=[u1,u2,u3,u4,u5]为五元向量集,它是通过极小化函数
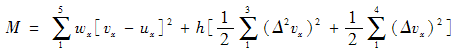 被修匀的,求解矩阵方程
被修匀的,求解矩阵方程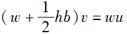 可得到修匀值向量u′=[v1,v2,v3,v4,v5]。则矩阵b为( )。
可得到修匀值向量u′=[v1,v2,v3,v4,v5]。则矩阵b为( )。
-
在关于硬币上抛例子中,我们仍取先验均值是1/2。现把此硬币上抛10次,得到7次正面。对于较少的上抛次数,我们认为对先验观点的置信度是对试验结果的置信度的两倍。按照已经得到的试验结果,T的修正“期望值”(即后验均值)是( )。
-
Linda将硬币上抛100次,得到45次正面,她说,0.45是T的“最可能”值,而并无进一步证据。为此,Frank决定提供进一步证据。他花费—个下雨天的厂午,将同一枚硬上抛1000次,得到600次正面。Linda承认FLank的结果应该是更可信的,但她想他可能数错了。她给他的结果的权4倍于她自己的结果的权。按照这个进一步的证据,Linda的关于T的“最可能”值(即后验众数)是( )。
-
若假设先验分布为Bata(a,b)分布,则a和b的值分别为( )。
-
表以下数据是死力的初始估计。对此,希望用不加权简单线性问归去拟合Gomperz形式。
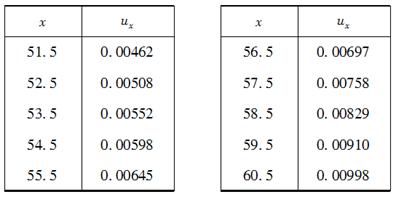
则Gompertz参数B和C的值为( )。
-
对于含n个内结点的一般情形,需要确定的参数个数是( )。
-
如果δ4ux+7=Δ4uy,则y为( )。
-
Gauss向前公式是ux+s=ux+c1Δux+c2Δ2ux-1+c3Δ3ux-1+c4Δ4ux-2+…下列系数计算正确的为( )
(1)c1=S;(2)c2=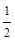 S(S-1);(3)c3=
S(S-1);(3)c3= S(S+1)2;(4)c4=
S(S+1)2;(4)c4=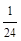 S(S-1)(S-2)(S+1);
S(S-1)(S-2)(S+1);
-
如果一个Everett型插值公式是十点公式,则这个公式中所包含的δ的最高幂次是( )。
-
F(s)被看成作用在ux上的—个算子,如果ux-1=4,ux=7,ux+1=15,则F(0)ux=( )。
-
设ux-2=2,ux-1=5,ux=7,ux+1=15和ux+2=22。设在四点插值公式中,A(s)=s,B(s)=1/4(1-s)。下列说法正确的为( )
(1)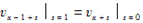 ;(2)B(0)=
;(2)B(0)=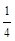 ;
;
(3)当B(0)≠0时,(1)中等式也能够成立。
-
当两点公式vx+s=A(s)ux+1+A(t)ux相切时,A(s)满足的特殊条件是( )。
-
考虑两点公式,其中A(s)=4s3-3s4,则下列说法正确的是( )。
(1)这个公式是相切的;
(2)这个公式是密切的;
(3)这个公式是光滑的;
(4)这个公式是再生的。
-
如果
 ,则
,则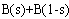 =( )。
=( )。
-
对于一个六点公式,给定A(s)=s和B(s)=1/6s(s2-1)。由
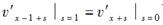 可推出( )。
可推出( )。
-
Henderson公式是
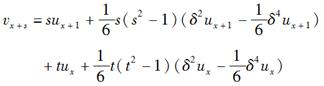
(1)它的精确次数为3。
(2)它是再生
(3)它是光滑的
(4)它是相切的
(5)它是密切的
以上说法正确的是( )。
-
某车队是一个同质的风险集合,各年的索赔次数独立同分布。对于给定的一辆汽车(风险参数为θ),其年索赔次数的均值和方差分别为μ(θ)和v(θ)。假设车队中的每一辆汽车具有相同的θ。如果从此车队中随机抽出一个由10辆汽车所组成的风险子集,则该风险子集的年期望索赔频率和年索赔频率的方差是( )。
-
如果假设每份保单的索赔次数服从泊松分布,而在一个保单组合中,不同保单的泊松参数服从参数为(α,β)的伽玛分布,已知记录了个体保单在n年内的经验索赔次数,则Bühlmann信度模型的信度因子为( )。
-
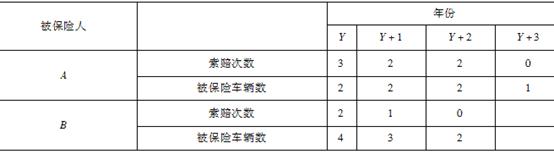
假设有两个被保险人A和B,他们在过去四年的损失数据如表所示。应用Bühlmann-Straub模型估计A和B被保险人的年期望索赔频率为( )。
表 被保险人的经验损失数据
-
有一家新开业的保险公司,以同行同险种的索赔频率0.148作为先验信息,先验分布假设服从参数α与1/β的伽玛分布。该公司的精算师有95%的把握认为真实赔款频率q与0.148的相对误差不会超过25%,结果第1个业务年度共签发了4000份保单,共发生600件索赔。则用贝叶斯方法估计索赔频率的后验概率为( )。
-
设某险种索赔额为常数,在正态假设下计算信度因子为1/2的期望索赔次数为( ),设p=0.90,k=0.05。
-
保险公司有2000份机动车辆车身险保险单,按照预期的赔款频率分别属于由表所示的三类A、B、C,现从这2000份保险单中随机地抽取一份并发现在过去的一年中未发生索赔,则这份保险单分别属于A、B、C类的概率分别是( )。(假定赔款次数服从泊松分布)。
表 风险分布

-
某保险业务的赔款频率约为0.02,平均赔付额为1324元,赔付额的方差为356929,则在r=0.10,p=0.95被认为具完全可信条件的最小赔款次数及最小业务量分别为( )。
-
若X服从参数为p的几何分布,p为随机变量且服从参数为(α,β)的贝塔分布,那么p的后验分布是( )。
-
某特定群体的历史数据是X=(X1,X2,…,Xn),其中Xj是独立同分布的复合Poisson随机变量,索赔次数的参数为λ,每笔赔付服从指数分布。如果根据索赔次数得到的信度因子是0.8,则用总索赔额计算的信度因子为( )。
-
设定某种疾病发病次数服从泊松分布,大约一半的人每年的发病次数为1次,另一半的人每年发病次数大约为2次,随机选取一人,发现其在前两年的发病次数均为1次,求该人在第三年内的索赔次数的贝叶斯估计值为( )。
-
完全可信条件要求
 在0.05E()范围内波动的概率为0.9,现在有新的标准,要求在kE()范围内波动的概率为0.95。若使这两种标准得到的风险数不变,则设k=( )。
在0.05E()范围内波动的概率为0.9,现在有新的标准,要求在kE()范围内波动的概率为0.95。若使这两种标准得到的风险数不变,则设k=( )。
-
基于样本数n=100的部分可信因子z=0.4,至少需要增加( )样本数使z增加到0.5。
-
每一时期的总理赔额S服从复合泊松分布,理赔强度的密度函数为f(y)=5y-6,y>1。样本数的完全可信标准要求S在0.05E(S)范围内波动的概率为0.9。如果相同的风险数运用的频数变量N,则每一个风险期的理赔次数在100r%E(N)内波动的概率为0.95,则r=( )。
-
理赔次数的概率分布函数为
 理赔次数在0.01E(X)范围内波动的概率为0.95,其中完全可信条件下,理赔次数的总期望值为34574,则q=( )。
理赔次数在0.01E(X)范围内波动的概率为0.95,其中完全可信条件下,理赔次数的总期望值为34574,则q=( )。
-
假设个体风险的索赔次数服从泊松分布,每次索赔额的变异系数为2,α=0.1,r=0.05,当个体风险的经验总索赔次数为( )时,用样本赔付额数据估计索赔强度的可信度为100%。
-
假设一年内的理赔次数服从均值为θ的泊松分布,其先验密度为
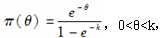 每年零索赔的非条件概率为0.575,则k=( )。
每年零索赔的非条件概率为0.575,则k=( )。
-
在一个保单组合中,每一个被保险人每年最多只发生一次理赔,其发生概率为q,先验密度为
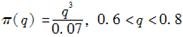 ,一个随机抽取的被保险人在第一年理赔一次,在第二年无理赔,对于该被保险人,则其后验概率为( )。
,一个随机抽取的被保险人在第一年理赔一次,在第二年无理赔,对于该被保险人,则其后验概率为( )。
-
对于某一特定风险,一年之内的理赔次数服从均值为p的伯努利分布,p的先验概率分布为[0,1]上的均匀分布,计算得到的贝叶斯信度估计值是观察理赔额的1/5时,则理赔额为0的年数是( )。
-
一个保单组合有100个独立的个体,其中25个个体的理赔限额为5000,25个的理赔限额为10000,50个的理赔限额为20000。在分类以前,这些风险个体拥有相同的损失额分布,即服从参数分别是θ=5000,α=2的帕累托分布,在分类以后,根据理赔报告可以显示出每一个范围的风险数,但是区分不开每一次理赔的理赔限额。这个报告准确显示了一个随机选择的理赔,位于9000~11000范围内,则该个体属于理赔限额为10000的概率为( )。
-
两个盒子每个里面都装了形状相同的10个球。第一个盒子里面有5个红球和5个白球,第二个盒子里面有2个红球和8个白球,每个球被抽中的概率是相等的。现随机抽选一个盒子,两个盒子等概率被抽中;从这个盒子中随机选出一个球,放回原盒子后再从该盒子中随机选出一个球。假设第一个被抽中的球是红色的,那么第二个被抽中的球也是红色的概率是( )。
-
在观察到任何理赔以前,你认为理赔额的大小服从参数为θ=10,α=1,2或者3的帕累托分布,三种情况等概率。现在观察到一个随机抽取的样本理赔额为20,则该样本点下次理赔额大于30的后验概率为( )。
-
一个完全独立个体的风险集可分为两类,每一类拥有相同的样本数。在类别1中,每一年的理赔数服从均值为5的泊松分布;在类别2中,每一年的理赔数服从参数为m=8,q=0.55的二项分布。一个随机选择的风险个体在第一年有3次理赔,在第二年有r次理赔,在第三年有4次理赔。Bühlmann信度估计在第四年的理赔数为4.6019。则r=( )。
-
某保险公司售出一个保单组合,过去的经验显示平均的理赔频率为0.425,期望值的方差为0.37,方差的均值为1.793。现在从保单组合中随机选择一种被保险人,该种类别的被保险人中再选出9个个体,一共有7次理赔。现在从这种类别中再选出5个个体,则这5个个体总理赔数的Bühlmann信度估计为( )。
-
已知两个风险A和B的损失金额服从表所示的分布。

其中风险A发生损失的概率是风险B的两倍。如果已知某个风险在某次事故中的损失额为300,则该风险下次损失额的Bühlmann信度估计为( )。
-
考虑一个由团体保单形成的保单组合。对整个保单组合而言,平均每个被保险人的期望纯保费为2400。对于不同的团体保单,平均每个被保险人的纯保费是不同的,不同假设均值之间的方差为500000。对于同一个团体保单,不同被保险人的纯保费也存在差异(用组内方差表示),所有团体保单的过程方差的均值为250000000。假设一份团体保单上年的索赔经验如下:被保险人数为240人,平均每个被保险人的经验纯保费为3000。该团体保单下每个被保险人的信度纯保费为( )。
-
假设风险集合中只有两个规模相等的个体风险,对每个风险的观察期均为3年,第一个风险的经验损失为:3,5,7;第二个风险的经验损失为:6,12,9。则第一个风险和第二个风险的Biihlmaan信度保费分别为( )。
-
理赔次数服从均值为m的泊松分布,理赔额的均值为20m方差为400m2。m的密度函数为
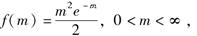 其中对于任何m,理赔额和理赔次数的分布是独立的。则总理赔额组内方差的期望为( )。
其中对于任何m,理赔额和理赔次数的分布是独立的。则总理赔额组内方差的期望为( )。
-
在大量的商业被保险人中你得到了如下数据:每个被保险人的损失是独立的,并且拥有相同的均值和方差,均值为25,假设期望的方差为50,条件方差的期望为10000。现随机选择一个被保险人得到表所列经验数据。则每个被保险人的Bühlmann-Straub保费为( )

-
用分数乘积法产生参数为0.5的泊松分布随机数。假设生成的一列均匀分布随机数为0.81899,0.81953,0.35101,0.68379,0.10493,0.83946,0.35006,0.20226,0.16703,则产生的泊松分布随机数为( )。[2008年真题]
-
现已利用Box-Muller方法产生了标准正态分布随机数0.8082,需生成模拟随机利率的随机数Y=
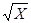 ,X服从参数为μ=5,σ2=4的对数正态分布,则得到的随机数为( )。[2008年真题]
,X服从参数为μ=5,σ2=4的对数正态分布,则得到的随机数为( )。[2008年真题]
-
给定在(0,1)上均匀分布的随机数序列{Ui,i≥1},现在要产生参数为α(α为正整数)和λ的伽玛分布的随机数V,V的概率密度函数为
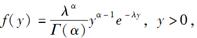 则随机数V的产生公式为( )。
则随机数V的产生公式为( )。
-
给定相互独立的服从(0,1)上的均匀分布的随机数U和V。现在欲利用Box-Muller的方法产生二个独立的、服从标准正态分布的随机数Y1、Y2,则可采用公式( )。
-
现有[0,1]上均匀分布的随机数:0.00582,0.00725,0.69011,0.25976,0.09763。利用反函数方法获得均值为1的泊松分布的随机数,则其对应的随机数为( )。
-
某公司的资产分布于股票、债券和固定资产三个部分。高级管理层希望了解公司次年资产总额的情况。显然上述三类资产次年的价值是随机的,分别设为X1,X2,X3,已知这三个随机变量的均值和协方差矩阵(单位:百万元)分别为:
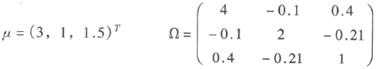
且已知利用n维正态分布模拟的三个标准正态分布随机数构成的随机向量为z=(z1,z2,z3)T=(1,-0.5,-1)T,则此公司次年的资产总额为( )万元。
-
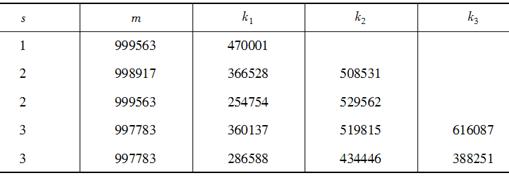
已知Skellam建议的高阶同余法的参数选择,如表所示。设选取的种子w0=671800,则采用Skellam一阶线性同余法生成在区间[0,1]上均匀分布的第3个随机数u3=( )。
-
已知来自均匀分布总体U[0,1]的随机数为u,则用反函数法计算指数分布的随机数为( )。
-
设已有[0,1]上均匀分布的随机数u,则用反函数法计算Weibull分布的随机数为( )。
-
取N=4,K=1234,w0=5678,用倍积取中法产生3个[0,1]区间上均匀分布的随机数分别为( )。
-
已知m=998917,k1=366528,k2=508531,w0=931125,w1=970710。用二阶线性同余法产生3个[0,1]区间上均匀分布的随机数,分别为( )。
-
下列公式中是用Box-Muller方法产生正态随机数的是( )。
-
关于泊松分布随机数的生成,下列陈述错误的一项是( )。
-
关于复合负二项分布的随机数的生成,下述说法正确的有( )。
(1)先生成负二项分布的随机数,再生成个别理赔额的随机数;
(2)先生成个别理赔额的随机数,再生成理赔次数的随机数;
(3)直接生成复合负二项分布的随机数。
-
要生成标准正态分布的随机数,下列方法中不能实现此目的的是( )。
-
已知两个标准正态分布的随机数0.70与-1.51,则相应的参数为μ=5.0,σ2=4.0的对数正态分布的两个随机数为( )。
-
已知参数为k=6,P=0.6的负二项分布,u1=0.345,u2=0.789,u1与u2是[0,1]区间上均匀分布的随机数,则与u1,u2相应的负二项分布的随机数分别为( )。
-
已知[0,1]区间上两个均匀分布的随机数u1=0.6341与u2=0.5791,则用Box-Muller方法生成的相应的标准正态分布的随机数分别为( )。
-
已知某种家用电器的寿命服从均值为1000小时的指数分布,为模拟此电器的寿命,现产生了[0,1]区间上一均匀分布的随机数0.2487,则模拟的这台电器的寿命为( )小时。
-
已知某负二项分布的部分分布函数,如表所示。现在已产生了[0,1]区间上均匀分布的随机数0.5302,那么与此随机数对应的该负二项分布的随机数为( )。
表 某负二项分布的分布列

-
有关随机数的产生,下列命题中正确的有( )。
(1)对于泊松分布随机数的产生,当泊松参数λ较大时,可用中心极限定理来产生该分布的随机数;
(2)对于负二项分布,当参数k与p中的p参数较大时,可用中心极限定理产生该分布的随机数;
(3)用分数乘积法可产生均匀分布的随机数;
(4)用物理方法(如放射性元素)产生的随机数是真正的随机数。
-
某保险人承保的风险服从复合泊松分布,泊松参数为λ=2,个别理赔额X的分布为[0,40]上的均匀分布。下列有关索赔总额随机数的产生,说法错误的有( )。
(1)先产生索赔次数随机变量的随机数n,再产生n个[0,40]上均匀分布的随机数xi,i=1,2,…,n,然后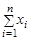 就是一个S分布的随机数;
就是一个S分布的随机数;
(2)先产生n个[0,1]上均匀分布的随机数,然后就是一个S分布的随机数;
(3)S分布的随机数不可能是0;
(4)S分布的随机数有可能是120。
-
已知某个负二项分布的部分分布列如表所示。若有一[0,1]区间上均匀分布的随机数u=0.7466,且P(N>3)=0.5173,那么对应的负二项分布的随机数为( )。
表 负二项分布的部分分布列

-
关于用中心极限定理产生N(0,1)分布的随机数,下列说法中正确的有( )。
(1)XN=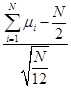 ,其中μi,i=1,2,…,N,是N个服从[0,1]上均匀分布的随机数,N越大,则X的值越接近于N(0,1)分布的随机数;
,其中μi,i=1,2,…,N,是N个服从[0,1]上均匀分布的随机数,N越大,则X的值越接近于N(0,1)分布的随机数;
(2)用六个[0,1]区间上的均匀分布随机数相加,然后将其和依次减去六个[0,1]区间上的均匀分布随机数,即可得到精确的N(0,1)分布的随机数;
(3)当对正态分布的尾部分布要求较高时,用中心极限定理产生随机数比较合适。
-
下列有关随机数的命题中,正确的有( )。
(1)倍积取中法产生均匀分布的随机数是伪随机数;
(2)放射性物理方法产生的随机数是伪随机数;
(3)Box-Muller方法是产生N(0,1)分布随机数的方法;
(4)极方法是产生[0,1]区间上均匀分布随机数的一种方法。
-
假设一个医疗保险合约由三个独立的被保险人组成,他们一年中的总看病次数服从二项式分布n=3,p=0.9。设每次看病的医疗费用为X,X的分布如表所示。
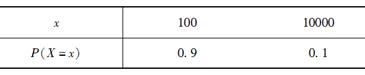
每年三人的总医疗费用超过5000元的部分由保险公司支付。
假设0.01,0.20为(0,1)均匀分布的随机数,用这两个数分别产生第一年和第二年的总看病次数。利用下列(0,1)均匀分布的随机数来产生每次看病的费用:0.80,0.95,0.70,0.96,0.54,0.01,则这两年内保险公司给付总数的模拟结果为( )。
-
假设随机变量X的密度函数为:
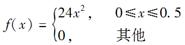
定义v是(0,1)均匀分布的随机数,已知v=0.125。使用反变换法,则X的随机观测值为( )。
-
已知分布函数为F(0)=0,F(1)=0.4,F(2)=1.0,F(x)在[0,1]和[1,2]上是线性函数,使用下列来自(0,1)均匀分布的随机数:0.2,0.4,0.7,用反变换法生成上面分布的三个模拟数,则这三个模拟值的均值为( )。
-
假设随机变量X的分布函数为:
(1)当x<0时,F(x)=0;(2)F(0)=1/2。
(3)当0<x<1时,F′(x)=x。
有(0,1)均匀分布的三个观测值:0.25,0.625和0.52。请按上述X的分布模拟三个样本X1,X2,X3,则X的样本均值为( )。
-
假设随机变量X的均值为μ,方差为σ2。如果想通过模拟来估计μ,要求估计与真值的相对误差小于5%的概率为0.9,则所需的模拟次数为( )。
-
一所学校有100名住校生,每人都以80%的概率去图书馆自习,如果要保证去上自习的同学能以99%的概率得到座位,则图书馆至少应设的座位个数为( )。
-
保险公司对于一个剧院的供电故障造成的损失提供四个月的保险赔偿。具体如下:
(1)每月有1000元的绝对免赔额。
(2)保险公司假设这个剧院每月的损失相互独立地服从均值为1500,标准差为200的正态分布。
(3)为了模拟这四个月的保险赔偿费用,保险公司运用反变换方法(小的随机数对应低的赔偿费用)。
(4)从(0,1)中随机抽取的4个数分别为:0.5438,0.1131,0.0013,0.7910。
则保险公司模拟得到的保险费用为( )。
-
对复合总索赔额的分布S进行模拟。首先进行索赔次数的模拟,然后进行索赔额的模拟。反变换法被用于索赔次数和索赔额的模拟(小的模拟值对应少的索赔次数和少的索赔额)。索赔次数服从m=5,p=0.5的二项分布。索赔额服从均值为2000,方差为20000000的帕累托分布。均匀随机数0.3被用于索赔次数的模拟,使用0.1,0.7,0.5,0.3中尽可能多的数进行索赔额的模拟,则S的模拟值为( )。
-
一个连续盈余过程的模拟。假设保险事故依照频率为2的泊松分布发生,理赔额服从帕累托分布,帕累托分布的参数α=2,θ=1000。初始盈余为1000,安全附加为0.2。保费的收取是连续的,当盈余为负则过程终止。
(1)假设有(0,1)均匀分布的随机数:0.83,0.54,0.48,0.14,请用反变换方法模拟理赔的时间间隔(小数字对应较短的时间间隔)。
(2)假设另有(0,1)均匀分布的随机数:0.89,0.36,0.70,0.61,请用反变换方法模拟理赔强度(小数字对应较少的理赔额),则根据模拟结果,在1时刻的盈余为( )。
-
模拟一个复合分布的赔付。其中:
(1)索赔次数N服从二项分布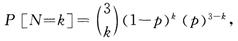 均值为1.8。
均值为1.8。
(2)赔付额均匀分布于{1,2,3,4,5,6,7,8)。
(3)赔付额相互独立,且与索赔次数相互独立。
(4)模拟索赔次数N,以及各次赔付的赔付额X1,X2,…,XN,然后再重复另一个N以及赔付额,直至得到满意的模拟数量。
(5)当模拟的索赔次数达到9,则不模拟赔付额。
(6)所有模拟运用反变换法,小的随机数对应相应的小值。
(7)得到的(0,1)均匀分布随机数为:0.5,0.1,0.7,0.3,0.4,0.7,0.5,0.9,0.3,0.1。
则第三次模拟N得到的总的赔付额为( )。
-
假设有来自未知分布F的两个随机抽样3和5,如果用
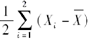 估计Var(X),其中
估计Var(X),其中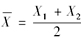 运用自助方法,则均方误差的自助法近似值为( )。
运用自助方法,则均方误差的自助法近似值为( )。
-
根据[0,1]区间上均匀分布的随机数列0.3,0.6875和0.95表示二项分布B(4,0.5)的数,则二项分布的随机数为( )。
-
根据[0,1]区间上均匀分布的随机数列0.1247、0.9321和0.6873来表示Possion(3)的数,则Possion分布的随机数为( )。
-
一个科学家做实验,成功率为0.6,X表示到第一次成功的试验次数。根据[0,1]区间上均匀分布R的随机数列0.85、0.38、0.63、0.22来模拟X。则到第三次成功的试验次数为( )。
-
假设
 则[0,1]区间上均匀分布的随机数列0.3、0.6和0.9模拟X的随机数列为( )。
则[0,1]区间上均匀分布的随机数列0.3、0.6和0.9模拟X的随机数列为( )。
-
随机变量X的分布函数FX(x)是两个指数分布的综合,分布1是均值为1的指数分布,权重为0.25;分布2是均值为2的指数分布,权重为0.75。在[0,1]区间上均匀分布的随机数0.7来模拟X,则X为( )。
-
假设通过模拟得到X1=1,X2=2,X3=3,X4=4,X5=5,则为了使E(X)估计值的标准差不大于0.05所需的模拟次数最少为( )次。
-
设随机变量X服从指数分布。通过模拟来估计总体FX(100)。假设Pn为样本中小于100的数目,n为样本数。则使得真值与估计值的相对误差不大于5%的概率为0.9所需的模拟次数为( )。
-
存在一个随机样本,样本的分布函数未知,已知样本标准差的区间为[2,3],则使得样本均值的0.9置信区间不大于1的最小样本量为( )。
-
假设某个理赔员处理一次索赔时间为0.5个小时或1小时,概率分别为0.5,小的随机数对应小的处理时间,随机数为0.1,0.6,0.4;用均匀分布随机数0.2、0.4、1.1来表示索赔事件在某2个小时时间段内发生的时间。该理赔员在该时段结束时处理索赔的状态为( )。
-
假设一个健康险的分布为符合泊松分布,索赔次数服从Possion(3),每次索赔额服从的分布函数为
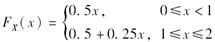 单位为万元。根据[0,1]区间上均匀分布R的随机数列0.1247,0.4121模拟前两年的索赔次数;根据[0,1]区间上均匀分布R的随机数列0.3,0.6和0.9模拟每次索赔额。保险公司对于每年的索赔额的免赔额为5000元。则这两年内保险公司给付总数的模拟结果分别为( )。
单位为万元。根据[0,1]区间上均匀分布R的随机数列0.1247,0.4121模拟前两年的索赔次数;根据[0,1]区间上均匀分布R的随机数列0.3,0.6和0.9模拟每次索赔额。保险公司对于每年的索赔额的免赔额为5000元。则这两年内保险公司给付总数的模拟结果分别为( )。
-
假设索赔次数服从二项分布(n=4,P=0.5),索赔强度服从均值为1000的指数分布,用均匀分布随机数0.21,0.53,0.67,0.13来模拟N,X1,X2,…,则总赔付额为( )。
-
假设一个车险的每月的损失分布服从均值为1000的指数分布。每月的免赔额为300,根据[0,1]区间上均匀分布R的随机数列0.213,0.376,0.754,0.109模拟前四个月的损失额,则保险公司前四个月的赔付额为( )。
-
索赔次数服从二项分布(4,0.5),赔付额服从帕累托分布(2.5,1000)。根据[0,1]区间上均匀分布R的随机数列0.2,0.8,0.3,0.1,0.5,0.6,0.9,0.3来模拟索赔次数和索赔额,当模拟的总索赔次数达到4时停止模拟。则保险公司的总赔付额为( )。
-
假设索赔次数服从Possion(3),理赔额服从帕累托分布(2,1000)。假设初始盈余为1000,安全附加为0.1,保费收取在年初,当盈余为负时保险公司则会破产。从随机数表选出的在(0,1)区间均匀分布内的随机数0.23,0.94,0.49,0.34,0.21来模拟理赔的时间间隔,用随机数0.58,0.97,0.88,0.67,0.44来模拟赔付额。则该保险公司在( )时破产。
-
随机抽取随机变量X的三个样本:1,6,8,应用Bootstrap方法计算下面估计的均方误差。下列说法正确的是( )。
(1)均值估计MSE(xe)=26/9;
(2)max(X)的均方误差为MSE(max(X))=77/27;
(3)min(X)的均方误差为MSE(min(X))=224/27。
-
某公司成功推出新产品的概率是20%,则200个新产品推出的过程中成功个数的标准差为( ),假设服从二项分布。
-
设损失X服从正态分布N(33,1092),则该损失分布的99%分位数( )。
-
设X~N(μ,σ2),则ES[X;p]为( )。
-
设下表中的理赔记录用韦伯分布来拟合,用其0.2和0.7分位点估计参数
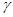 为( ),韦伯分布的分布函数为
为( ),韦伯分布的分布函数为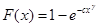 。
。

-
已知原保险人与再保险人签订以下合同:最高承保能力为60万元:
①若赔款x在满足x≤6万元时,由原保险人承担;
②若赔款x在满足6<x≤10万元时,超过6万元的赔款由再保险人承担;
③若赔款x在满足10<x≤35万元时,赔款由双方承担一半;
④若赔款x在满足x>35万元时,再保险人承担20万元。
如果X~U(0,60),其中X表示赔款额随机变量,则再保险人赔款额的数学期望为( )。
-
设某险种的损失额X具有密度函数(单位:万元)为

假定最高赔偿限额D=4万元,赔付率p=3.2%,则净保费是( )元。
-
有100000人参加了汽车车辆险,每车每年发生车辆损失的概率为0.005,估计车辆损失在475辆到525辆之间的概率是( )。
-
设某运输车队每年大约事故发生次数服从泊松分布,参数λ可取1.0或1.5,又设λ的先验分布为:P(λ=1.0)=0.4,P(
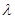 =1.5)=0.6。假如某一年该车队发生了三次事故,则λ的期望为( )。
=1.5)=0.6。假如某一年该车队发生了三次事故,则λ的期望为( )。
-
设索赔频率q服从以a,b为参数的贝塔分布,其先验分布的密度函数为(0,1)上均匀分布,即
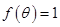 ,
,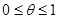 ,
, ,
,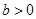 。在已知
。在已知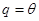 的条件下,每份保单的索赔
的条件下,每份保单的索赔
次数 服从参数为θ的二项分布,即:
服从参数为θ的二项分布,即: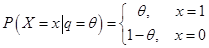 。若
。若 ,
,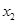 ,
,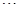 ,
,
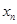 为
为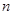 份保单索赔次数的观察值,则
份保单索赔次数的观察值,则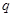 的可信度因子为( )。
的可信度因子为( )。
-
从一组有效保单中抽取100份,发现有3个索赔,假如该险种的索赔频率
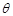 的先验分布为Beta(2,200),则的后验分布为( )。
的先验分布为Beta(2,200),则的后验分布为( )。
-
给定在(0,1)上均匀分布的随机数序列
 ,现在要产生参数为
,现在要产生参数为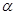 (为正整数)和的伽玛分布的随机数V,V的概率密度函数为
(为正整数)和的伽玛分布的随机数V,V的概率密度函数为 ,
, >0,则随机数V的产生公式为( )。
>0,则随机数V的产生公式为( )。
-
假设某险种的损失记录如下表所示:

如果折现利率为10%,现在用参数为(3,)的帕累托分布拟合2008年的平均损失金额。其中参数为(,)的帕累托分布的密度函数为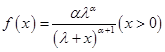 。则的矩估计值为( )。
。则的矩估计值为( )。
-
根据保险公司风险资本比率所在的不同范围,监管部门会采取相应的措施。当风险资本比率( )时,属于授权控管水准,监管部门可以对保险公司采取重整或清算的行动。
-
某公司承保业务如下表所示:

在满足所需假设条件下,业务一和业务三合并业务的财务稳定系数为( )。
-
一组样本数据满足以下条件:
(1)均值=35,000
(2)标准差=75,000
(3)中值=10,000
(4)90%分位数=100,000
(5)样本服从Weibull分布
用分位数估计法估计Weibull分布的参数γ,估计结果( )。
-
某非寿险公司保险金额的经验分布如下表所示:
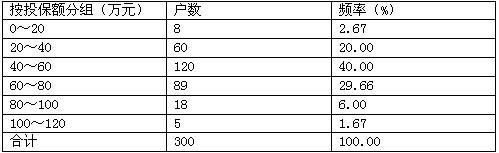
假设各组数据分布均匀,用线性插值的方法估计一个企业财产保险的保险金额不低于50万元的概率为( )。
-
以下说法正确的是( )。
-
下表给出某财产险2009年和2010年的一年期签单数据,假设每个季度签单保单的签单时间、风险分布都在相应季度中均匀分布,不考虑退保因素,则2010年的已承担风险量为( )。表 新签或续保的保单数目

-
对于纯保费法和损失率法,下面说法不正确的是( )。
-
用平行四边形法计算等费率因子时,假设仅考虑一个年度,且保费增长只在该年度出现一次,而在此之前的年度保费没有增长。当保费增长在该年度1月1日生效时,等费率因子为1.04,如果保费增长不是在年初,而是在4月1日增长,那么等费率因子是( )。
-
已知费用比率数据:
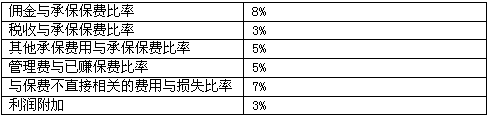
则目标损失率T为( )。
-
在已知θ的条件下,损失随机变量X的条件密度函数是
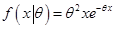 ,x>0,,参数θ的先验分布密度函数是
,x>0,,参数θ的先验分布密度函数是 ,θ>0。参数θ的后验分布密度函数π(θ|x)的正确表述是( )。
,θ>0。参数θ的后验分布密度函数π(θ|x)的正确表述是( )。
-
续第10题,给定X1=x1,X2的贝叶斯保费是( )。
-
已知:
(1)赔款额X满足:E[X|u]=u,Var[X|u]=500;
(2)随机变量u的期望为1000,方差为50;
(3)前三起赔案的赔款额分别为:750,1075,2000;
用Buhlmann信度方法估计下一赔案的预期赔款额为( )。
-
某保单每月赔款次数可看做均值未知的泊松分布。已知如果前一个月没有赔案发生时,未来一个月的预期赔案次数的参数估计为1/30;如果前两个月没有赔案发生时,未来一个月的预期赔案次数的参数估计为1/55。如果前三个月没有赔案发生时,未来一个月的预期赔案次数的参数估计为( )。
-
某财产保险公司在一年内的保费收入如下表所示(单位:千元):

假设保单期限为一年,且保费收入在季度内是均匀的,到年末按季提取未到期责任准备金应是( )千元。
-
已知累积已付赔款额如下表所示,则各事故年在日历年2010年的总支付赔款应为( )。累积已付赔款 单位:千元
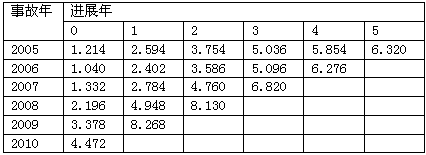
-
已知累积已报案赔款流量三角形如下表所示,若采用最近2年原始加权法计算进展因子,则最终累积进展因子0-∞的估计值为( )。累积已报案赔款 单位:千元
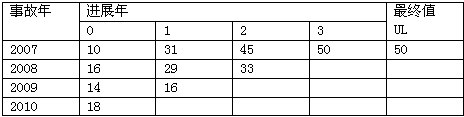
-
考虑三张一年期的保单A,B,C,保费都为1000元。保单A在2009年6月1日签单,保单B在2008年7月1日签单,保单C在2007年6月10日签单。在2009年12月31日,利用七十八法则计算未到期责任准备金,结果为( )。
-
某保险公司的直接理赔费用和已付赔款如表1和表2所示:表1 累积直接理赔费用 单位:元
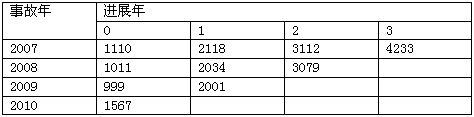 表2 累积已付赔款 单位:元
表2 累积已付赔款 单位:元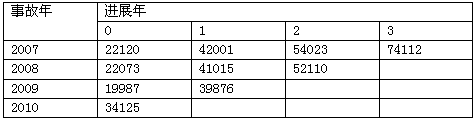 用已付ALAE与已付赔款比例法计算ALAE准备金为( )。
用已付ALAE与已付赔款比例法计算ALAE准备金为( )。
-
给定下面的逐年进展因子:f0-1=1.41,f1-2=1.22,f2-3=1.16,f3-4=1.08,f4,∞=1.04,已知在评估日2010年12月31日,2009事故年的已赚保费为1,000,000元,期望赔付率为0.6,用B-F法计算2009事故年的未决赔款准备金为( )。
-
对于再保险的分类,下面说法中正确的是( )。
-
对于再保险的准备金评估,下面说法中不正确的是( )。
-
已知信息:
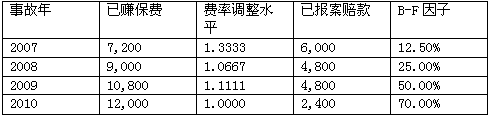
利用CapeCod方法,计算预期损失率(ELR),结果为( )。
-
常用来作为损失额的理论分布有( )。
-
假设危险单位在经验期内均匀分布且保费期限为1年,已知下面数据,
表1 费率增长情况

表2 日历年均衡保费 单位:万元

下列用平行四边形法得到的相对于2011年7月1日的等费率因子和近似均衡保费正确的是( )。
-
以下关于Buhlmann模型的参数估计是无偏估计的是( )。
-
下列费用项目属于间接理赔费用(ULAE)的是( )。
-
下列陈述中不正确的是( )。
-
利用So(t)估计S(t),则S(5)、S(12)的估计量分别为( )。
-
运用上述数据估计(1)2q0为____;(2)S(3)为____;(3)q3为____。( )
-
若样本的生存分布为区间(0,5]上的均匀分布,则
 的值分别为( )。
的值分别为( )。
-
计算
 和
和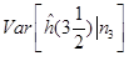 的估计值分别为( )。
的估计值分别为( )。
-
计算
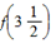 和
和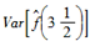 的估计值分别为( )。
的估计值分别为( )。
 Copyright 2023 上海欣师教育科技有限公司
Copyright 2023 上海欣师教育科技有限公司